Présentation
Nagios permet de superviser un ensemble de machines, et d’envoyer des alertes lorsque des seuils sont atteints.
Il s’agit d’un outil critique lorsque l’on fait de l’hébergement, car il faut avoir une visibilité sur la santé de l’ensemble du parc.
Contexte
J’ai travaillé avec Nagios en production pendant toute mon alternance ainsi que mon stage. Il supervise plus de 300 machines et 2000 services en permanence.
Projet
Il s’agissait d’administrer le serveur Nagios, d’ajouter/supprimer des hôtes et services en fonctions de l’état de la production.
Nagios étant un outil utilisable sur Linux, l’ensemble de la configuration se fait par fichier.
On définis un nouvel host comme ceci, à ajouter dans la configuration de Nagios :
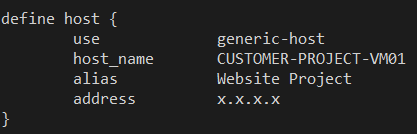
Le template par défaut ‘generic-host’ défini l’action à effectuer par défaut sur un host, ‘check_alive’ (ping) ainsi que sa fréquence.
A chaque nouvel ajout il suffit donc d’insérer un host dans ce fichier afin de créer un nouvel host dans Nagios.
Les services permettent de faire des checks plus poussés, notamment en récupérant le résultat de scripts exécutés sur l’hôte distant, via un agent.
Voici le template d’un service suivant le même pattern :
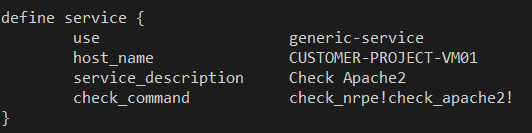
En spécifiant le même host que précédemment, Nagios va utiliser l’adresse correspondante pour effectuer ses contrôles. L’agent à installé sur l’hôte distant est NRPE, qui permet d’associer le nom d’un check à une commande linux.
Par exemple sur cette hôte, on a installé et configuré l’agent NRPE pour que la commande check_apache2 fasse appel à un script local:

Le script peut alors retourner un code erreur 2 si erreur critique, 1 si avertissement et 0 si tout va bien.
La plupart des scripts NRPE sont disponibles gratuitement, mais pour des besoins internes j’ai eu à écrire plusieurs scripts moi-même.
Une fois que l’on a déclaré tous les hosts et services qui doivent être supervisés, on peut vérifier l’état global du parc grâce à l’interface web :

Chaque seuil d’alerte peut être contrôlé directement dans le script qui renvoie l’état d’un service.
Les contacts sont un objet qui se présente sous la même forme qu’un host :
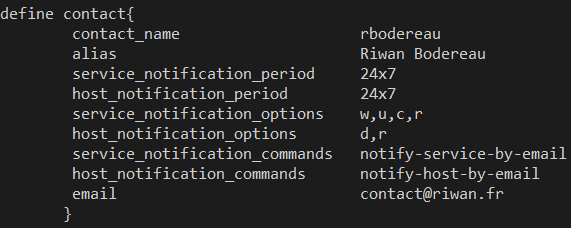
Par défaut Nagios envoie des e-mails pour avertir d’un problème, mais il est possible de configurer d’autres services comme les SMS.
Les contacts à utiliser peuvent être spécifiés pour chaque host/service ou alors dans le template ‘generic-host’ ou ‘generic-service’ par défaut.
Il est important de mettre des seuils d’alerte réalistes, et de les mettre à jour régulièrement en fonction du besoin. On peut très vite se retrouver enseveli sous des tonnes de mails Nagios et de faux-positifs qu’on ne prend plus le temps de lire, et qui peuvent cacher un réel incident.
Compétences liées